High-performance computing, machine learning (ML) and AI, and scientific workloads must be built to be scalable, a requirement that is often difficult for traditional filesystem storage solutions to meet. Object storage provides a fast, networked, and highly scalable storage option for these use cases, but there are some inherent performance and compatibility problems that need to be solved when using object storage with your existing scripts and applications.
In this article, we break down the types of performance requirements that might exist for object storage, and show how cunoFS achieves higher throughput performance with existing object storage solutions.
cunoFS turns any S3-API compatible object storage solution into a high-performance, POSIX-compatible filesystem that can be used with your existing code, often with better performance than native APIs and SDKs. cunoFS works on all major operating systems and is compatible with all popular object storage systems, both cloud and on-premises, including AWS S3, Azure Blob Storage, Google Cloud Storage, NetApp StorageGRID, MinIO, and Dell ECS.
High-performance storage requirements: what does “high-performance” mean to you?
”Performance” can mean different things in different use cases — each project measures success differently, and there can be some confusion as to whether a storage solution is performing well depending on the requirements.
When discussing performance in regard to computer storage, we may usually be talking about one of the following metrics:
| Performance metric | Use cases/practical effect |
IOPS (higher is better) Read/write operations per second | Databases and real-time applications that read and write lots of transactional data in quick succession |
Throughput (higher is better) Amount of data that can be transferred in a second | Big data applications like streaming video, machine learning, and analytics requiring large datasets |
Latency (lower is better) The time it takes to complete a single read/write operation (usually including any network requests) | Real-time applications including financial dashboards, gaming, and anything timing-critical |
Durability/reliability Ability to retain data without loss/corruption and the operability of the storage medium itself | Long-term storage, mission-critical storage, anything where long-term data integrity matters and the data spends significant time at rest |
While, arguably, a directly-attached RAID array of SSDs will always be the most performant in most categories, this is expensive, impractical, and doesn’t scale well. So teams tasked with selecting a storage solution for their project have to make tradeoffs to focus on the performance metric that matters most to their goals.
The strong suit of object storage is its throughput and scalability performance. Workloads like machine learning are most affected by these two metrics, as they need to be able to read from large, ever-expanding datasets. As object storage is optimized for throughput and scalability, it does not offer the best latency performance, which is not a problem as latency and IOPS are generally secondary considerations for these kinds of workloads. Object storage performs highly on durability metrics when configured with redundancy (for example, using MinIO’s erasure coding).
Other object storage solutions often bottleneck their own performance and add roadblocks
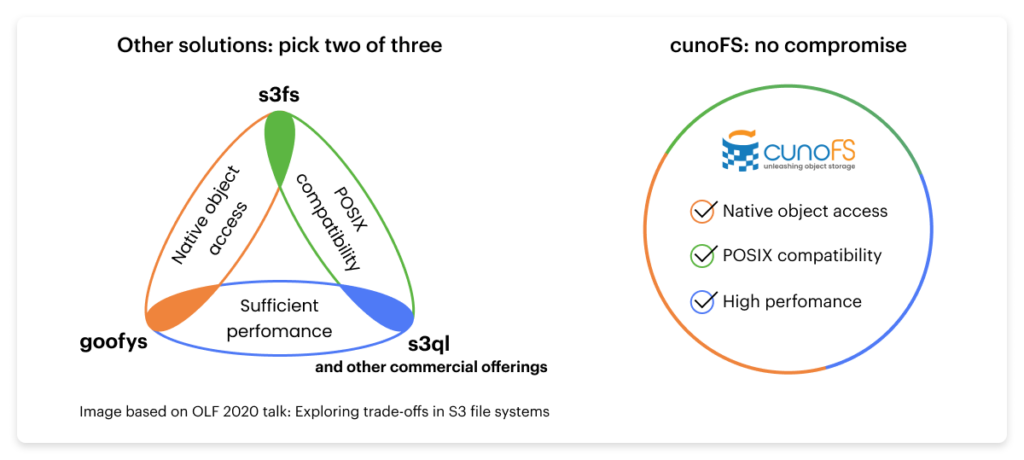
Most workflows are developed locally, or originate from legacy systems that use a standard POSIX-compatible filesystem. Local filesystems work very differently from object storage. When the time comes to scale up and implement object storage in your project, usually because you need the scalability and the throughput performance, you usually have to find new compatible tools or rework your code to use vendor-specific object storage SDKs, APIs, or CLIs. As most of these interfaces are neither feature rich nor POSIX compliant (e.g., not allowing for directories and directory listing), you must tailor your code specifically to them, leading to vendor lock-in, unexpected behavior, and a generally hobbled development process.
Developers and users benefit when they can continue to build on their existing POSIX-compliant code and deploy their workflows to any environment (local, managed, or serverless) knowing that it will work exactly as they intend with object storage. While some object storage solution vendors try to reduce development friction by offering POSIX access (making their object storage appear like a native filesystem), they are usually architected in a way that introduces performance bottlenecks — for example, by adding nodes to store metadata or intermediate storage gateways.
These hurdles mean that developers are rarely able to fully leverage the throughput and scalability advantages that object storage provides.
How cunoFS lets you take advantage of the high performance of your networked object storage solution
cunoFS directly addresses these problems by maximizing the throughput between object storage and your applications and scripts and providing a no-compromise POSIX-compatible interface that lets you access your files as-is without scrambling them or requiring intermediate storage gateways.
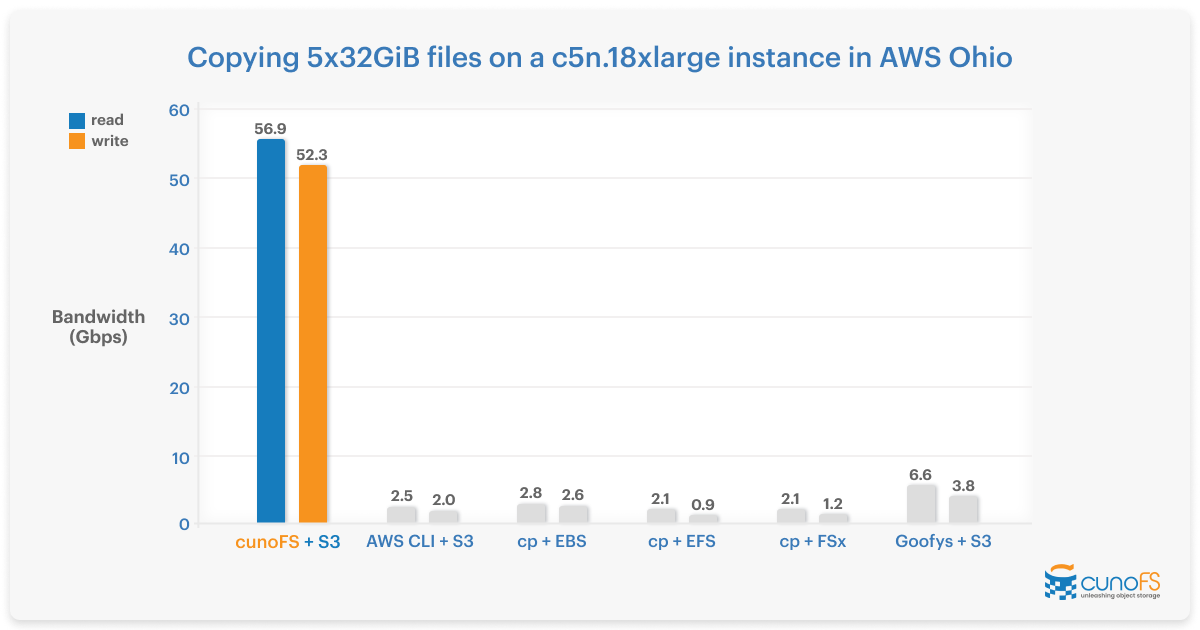
The cunoFS filesystem layer is a client-side application, so — unlike other solutions that are far removed from the actual data use — it can anticipate data reads and writes to reduce bottlenecks, and is able to store POSIX metadata without the need for additional gateways or databases.
cunoFS lets you take full advantage of the throughput performance that object storage provides, and works over both LAN and WAN to give you native filesystem access to almost any object storage provider. Unlike with object storage SDKs, APIs, and other less performant filesystem layers like goofys and s3fs-fuse, you can work directly on data stored in S3 and object storage, without needing to stage files locally.
We also provide tools targeting specific high-performance and scientific use cases (we’d love to hear about yours!).
Our cunoFS PyTorch module builds on our ability to inspect and predict file access to optimize data loading in machine learning applications, providing up to a 13x increase in performance over other data loading solutions.
Case study: how cunoFS helped a leading pharma company achieve high performance with their object storage
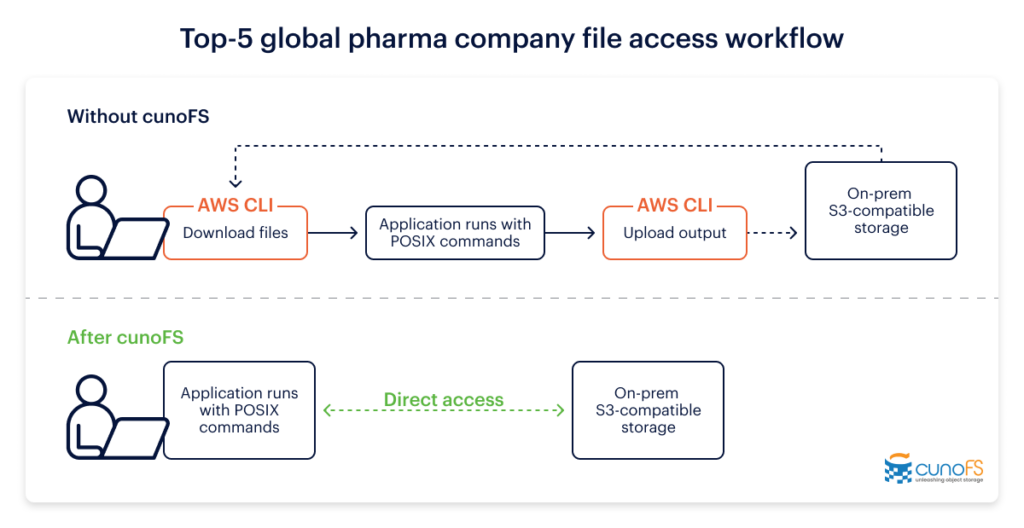
To see just how much cunoFS improves the performance of on-premises object storage, take a look at our case studythat examines both the performance and workflow improvements cunoFS brought to a leading global pharmaceutical company. They saw a real-world 5–13x performance increase for their existing on-premises object storage solution when coupling it with cunoFS, and were able to greatly simplify their workflows, leading to improved productivity from their technical teams.
Book a meeting with our engineers to chat about your use case for high-performance object storage, ordownload cunoFS now and try it for yourself — it takes only minutes to get up and running.