

Details on how cunoFS differs from other solutions
Technology in Detail


cunoFS is a high throughput, POSIX compatible filesystem using object storage, where each file is a directly accessible object, and each object is a directly accessible file.
cunoFS in Action

Background: Object Storage vs File Storage
Object storage has quite different characteristics from normal file storage. These characteristics allow object storage to scale far beyond regular file systems, delivering incredible throughput, and utilizing erasure coding for lower costs. However, object storage is generally not POSIX compatible.
| File Storage | Object Storage |
| Directory structure | Flat, no directory structure |
| Scalability is hard | Highly scalable |
| POSIX compatible: UID/GID, Symlinks, Hardlinks, ACL, … | Not POSIX compatible |
| Direct access through OS (syscalls) | REST API (HTTPS) inside application |
| Strong consistency guarantees | Varies but usually weaker consistency |
| Usually single site | Often geo-distributed |
| RAID, duplication, or other redundancy | Erasure coded (highly efficient) |
| Typically low(er) latency | Typically high(er) latency |
| Fast Random Access Write | Replace whole object at a time |
This table highlights some of the key differences between File Storage and Object Storage.
Background: Competing Approaches to Utilizing Object Storage
There are quite a number of commercial POSIX file systems that use object storage, hiding it behind regular file storage as a second class storage tier – an archival tier for old or infrequently accessed data.
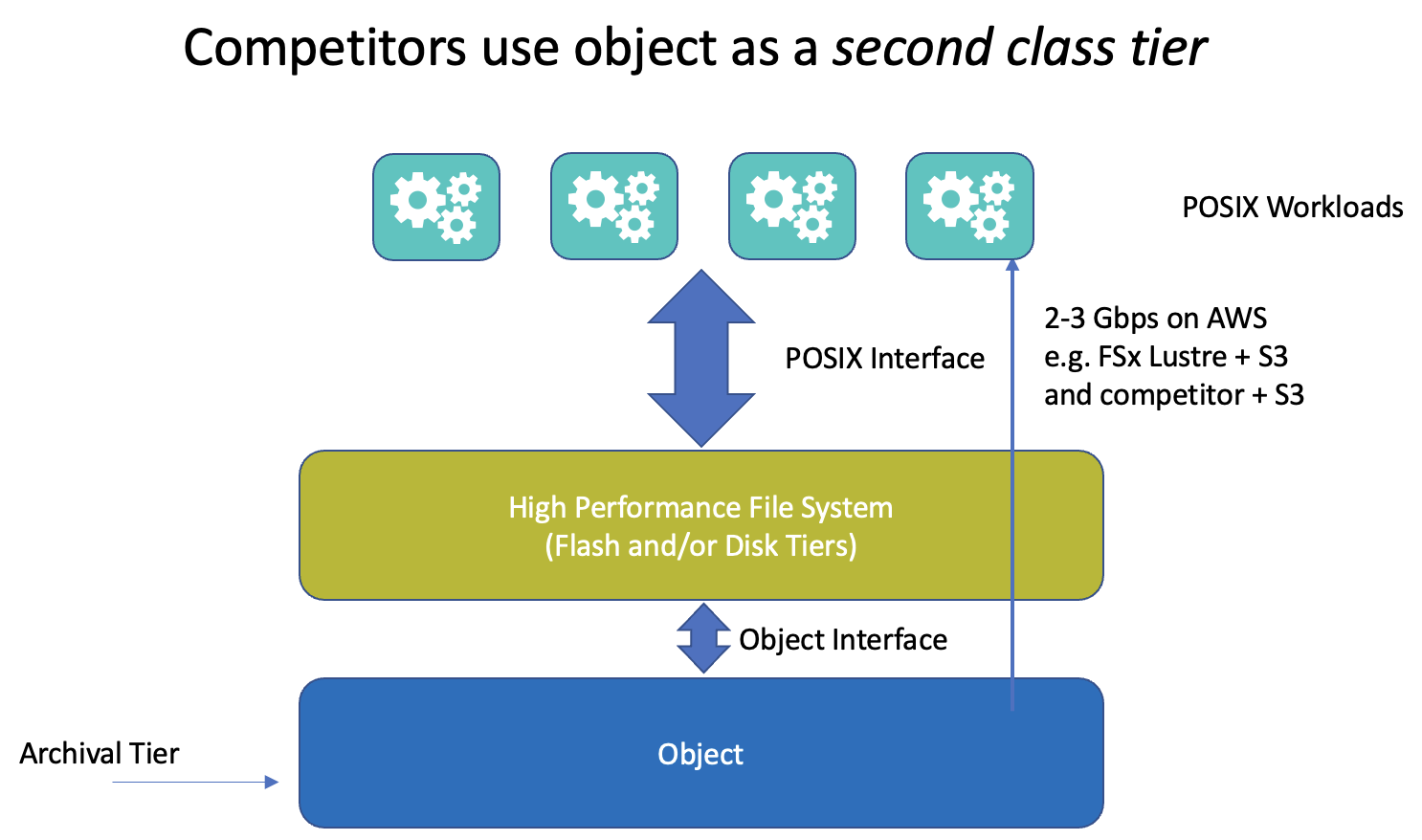
In such a solution, if something is needed from object storage, it is reconstituted back into the primary POSIX storage layer for access. This is a shame given the much higher levels of throughput that may be available under object storage compared to the file storage in front of it. Indeed some common solutions we see on AWS deliver only 2-3 Gbps throughput when accessing files stored in S3 through POSIX.
There are also competing commercial and open source approaches that try to use Object Storage for a POSIX file system by treating object store more like block storage, where chunks of data (often deduped and compressed) from within a file can be stored, and then a separate database is used to maintain POSIX metadata and information on how the chunks can be reconstituted back into files.
Competing Approaches Scramble Data
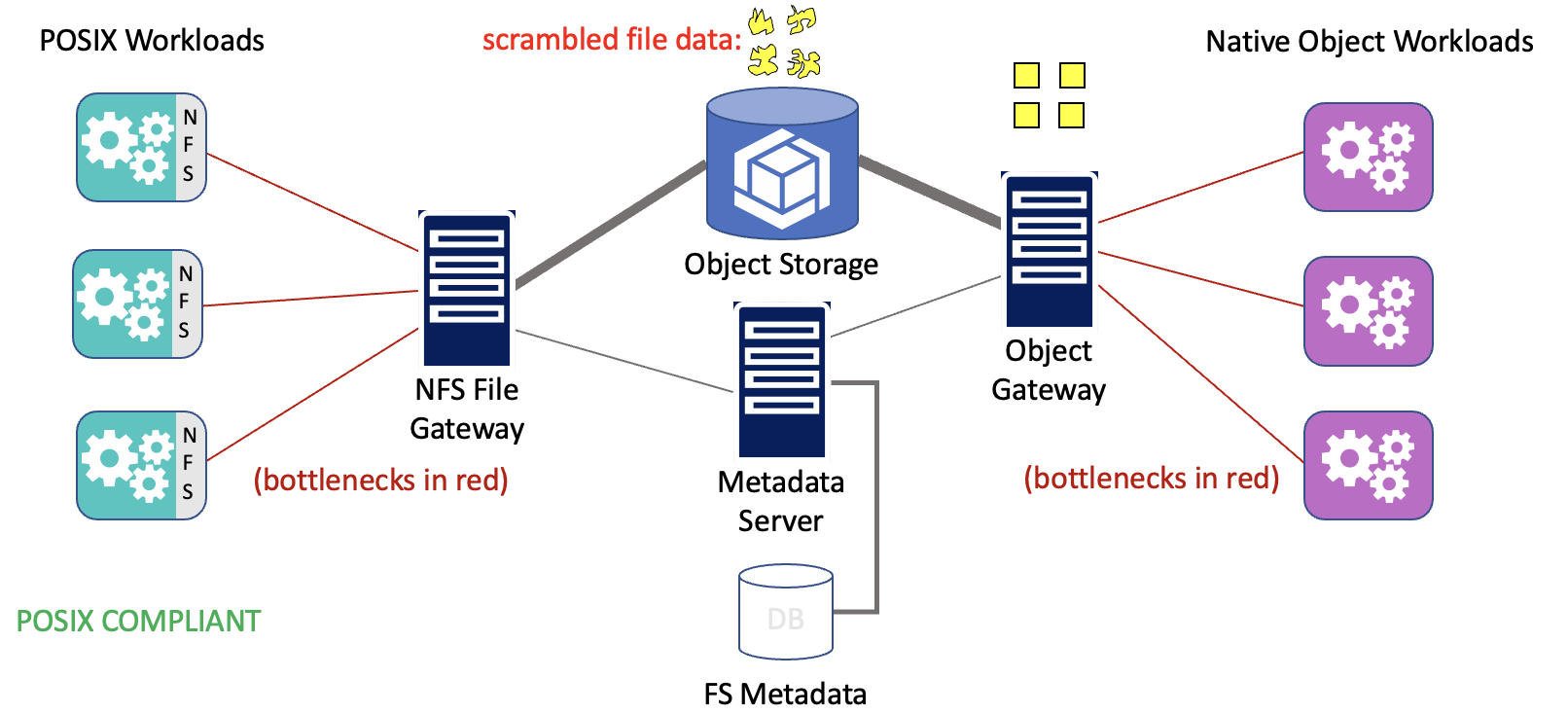
With these approaches, the files are necessarily scrambled on object storage, so they are no longer directly accessible from e.g. S3. Thus these solutions usually provide a separate S3 Gateway to unscramble the files back from the chunks stored on the object storage. In addition, there is usually a metadata server to hold the database. Typically, an NFS gateway is deployed for access by POSIX workloads. The reconstitution back into files can be a major performance bottleneck, and when multiple nodes are trying to access the gateways, there are severe scalability issues that can cripple performance.
Introducing cunoFS
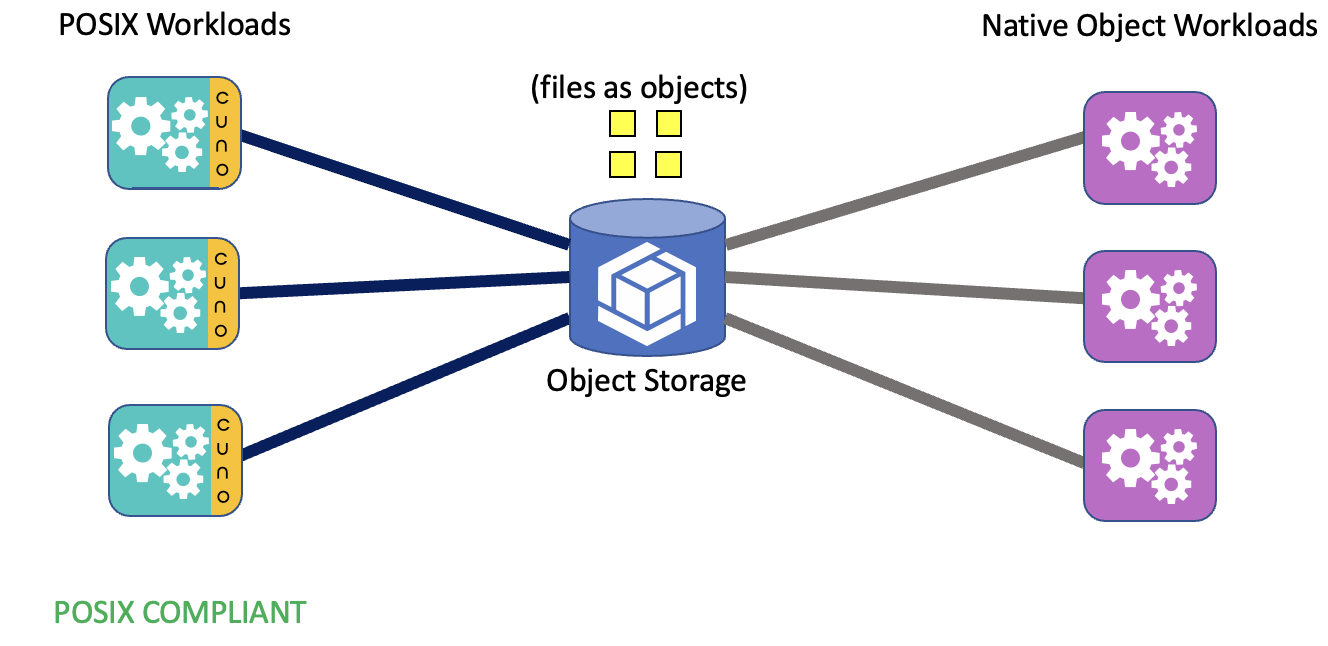
With cunoFS we wanted to radically change how object storage is used and turn it into a first class direct tier for POSIX file access. Here each POSIX workload on each node can directly access Object Storage (such as S3), and each object-native workload can also directly access the Object Storage. We do this without introducing any gateways and without scrambling the data. Each file is directly stored as an object and each object is directly accessible as a file. This means workloads can scale across nodes to as much as the Object Storage itself can handle (over 10+ Tbps in the case of AWS S3). cunoFS takes care of the POSIX semantics including consistency guarantees (for POSIX workloads only), symlinks/hardlinks, POSIX permissions, ACL, mode, timestamps, etc. This POSIX metadata is stored directly on the Object Storage as well – unlike other approaches there is no separate database required.
cunoFS Fusion
In addition to regular cunoFS operation, we introduce cunoFS Fusion which is available on Professional and Enterprise licenses.
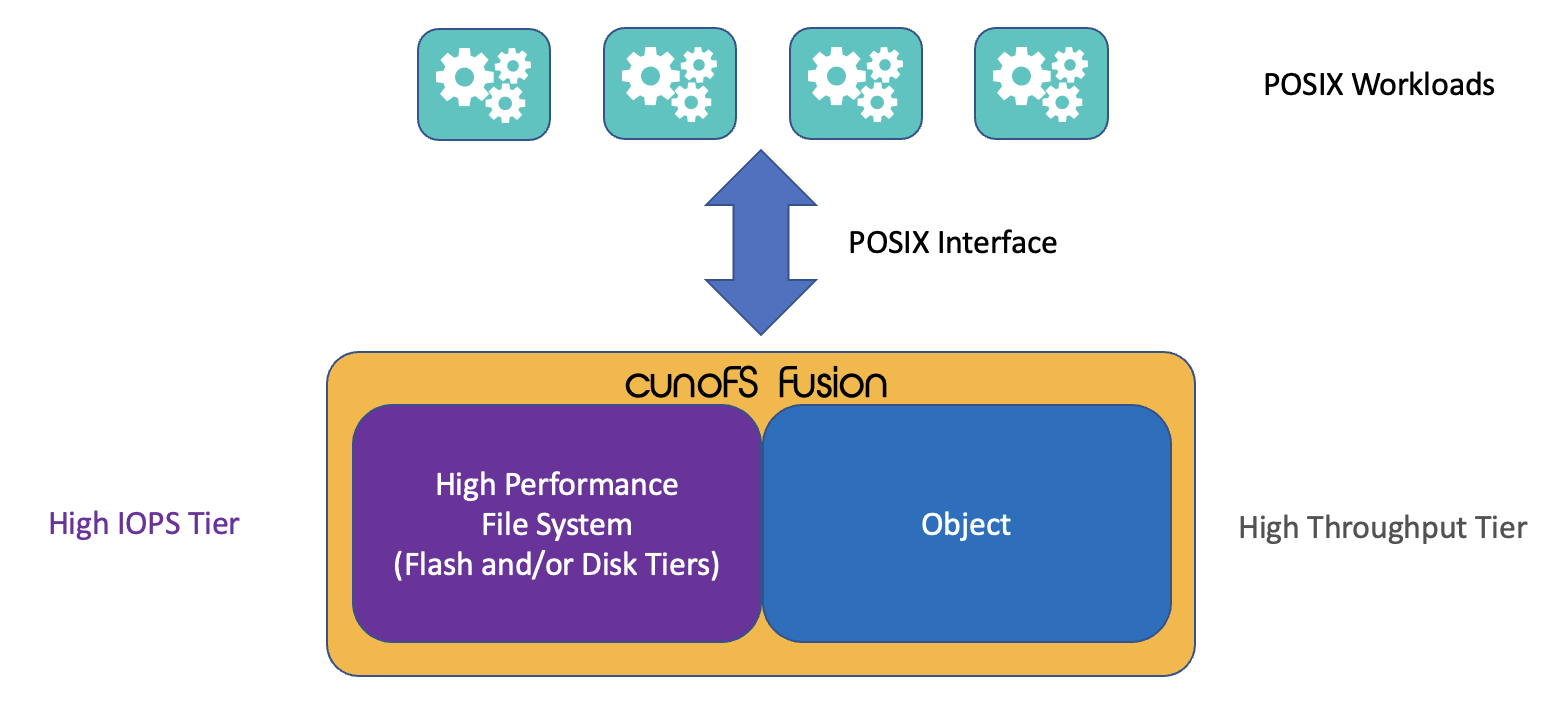
The cunoFS Fusion product allows customers to pair an existing file system capable of high IOPS, with the high throughput and low cost of object storage, with both treated as first-class storage tiers. This combines the best of both worlds – enabling both big performance gains and significant cost savings. For example, some throughput-limited workloads like Genomics or Machine Learning can see large performance gains from being moved to a first-class object storage tier. It can also be paired with a file system like AWS FSx Lustre or EFS to deliver higher combined performance and reduce costs for general workloads.
Performance Improvements
We’ve spend many years developing cunoFS to deliver high performance and scalability. We often get asked about how we achieve the performance improvements, and there are many layers. To understand some of this, one first needs to understand the problems with existing approaches.
The problem with FUSE-based File Systems
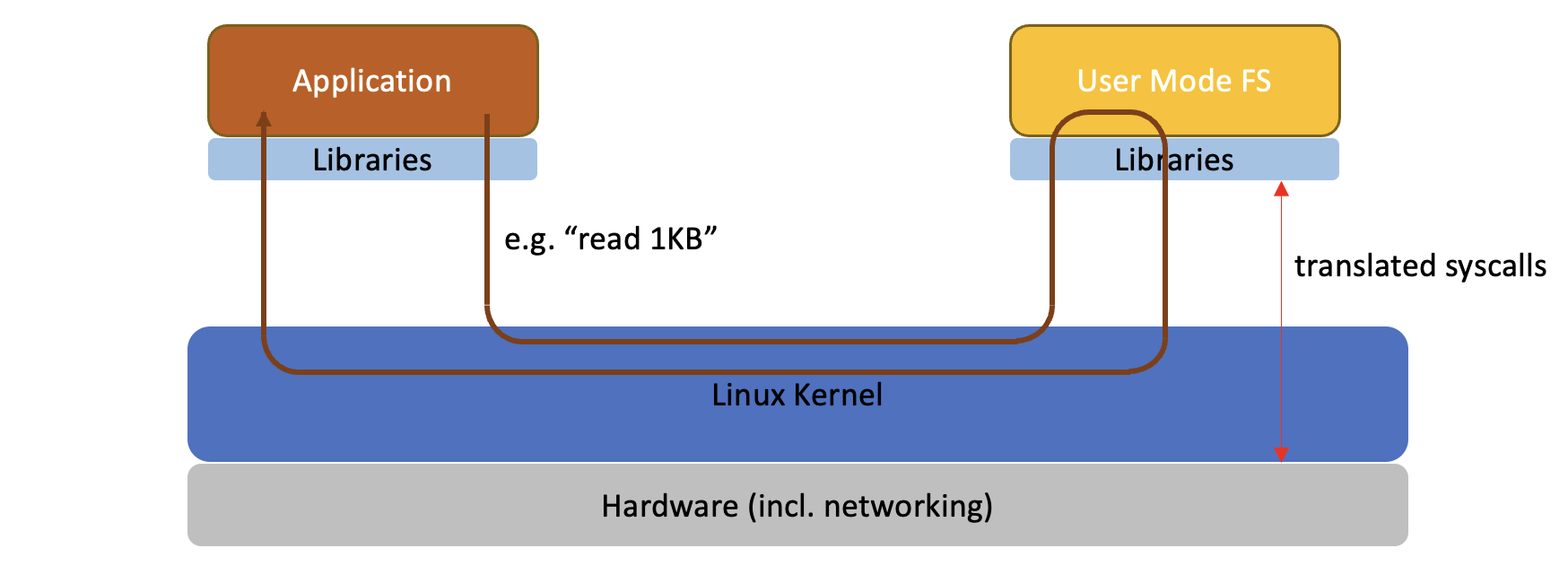
On Linux, FUSE enables a user-space application to present a virtual file system at a mount point. There are solutions like s3fs and goofys that use FUSE as a file system layer for object storage. Unfortunately, FUSE introduces significant overheads – each time an application does an operation on the virtual file system, there are typically at least four context switches involved between user-space and the kernel to service the request.
The problem with SHIMs
Another approach to handling virtual file systems is to use a SHIM (such as LD_PRELOAD on Linux). The SHIM library can intercept library calls made by an application to the virtual file system, and handle it without necessarily going to the kernel. Applications that depend on libraries in this way are called dynamic binaries. By eliminating expensive context switches, the SHIM approach can significantly improve performance, but unfortunately the SHIM cannot handle static binaries or semi-static binaries (such as some Go binaries) that directly talk to the kernel via syscalls rather than through a library. This means that it only works with some binaries.
cunoFS Direct mode
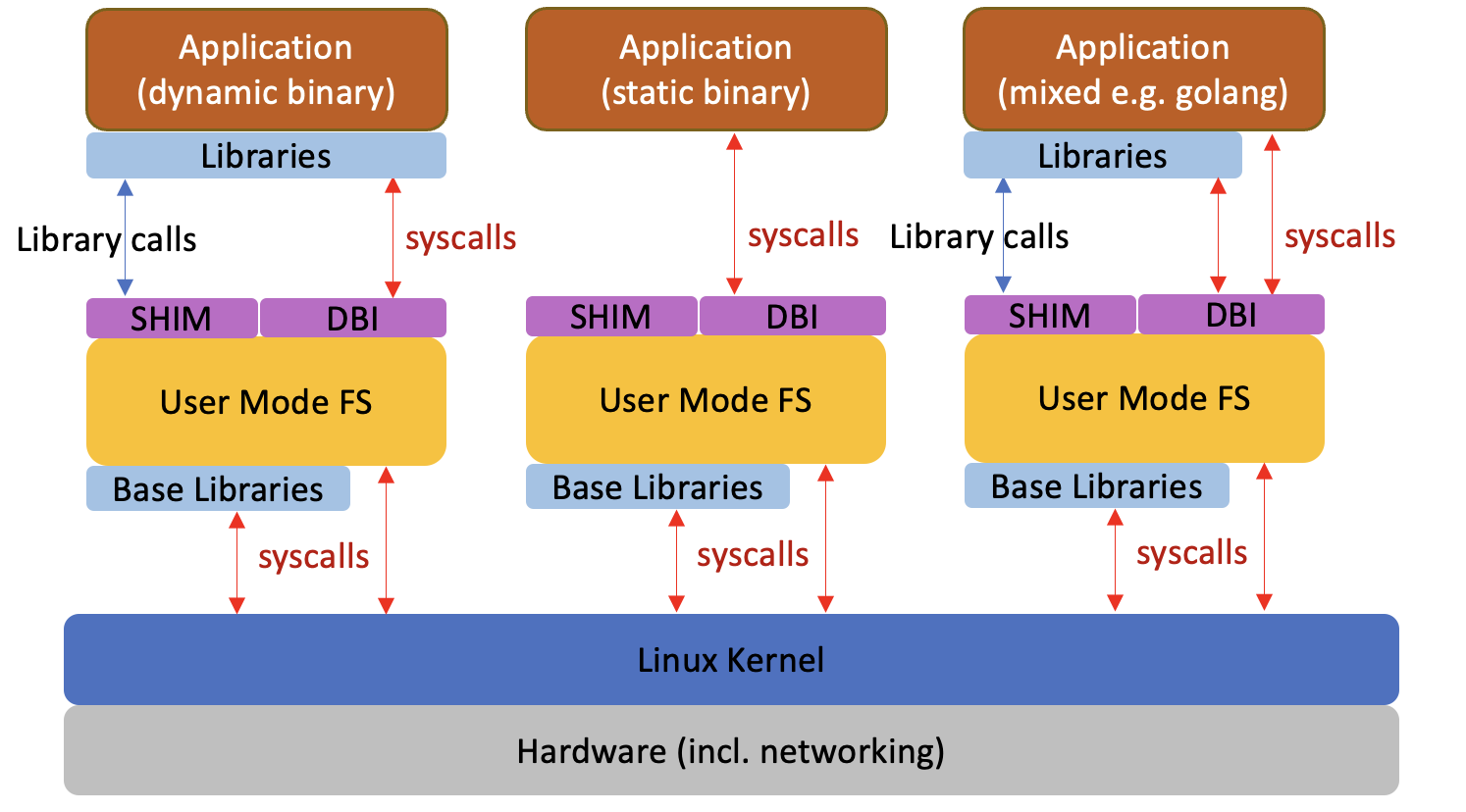
With cunoFS, the SHIM approach was combined with ultra-fast Dynamic Binary Instrumentation (DBI). This allows cunoFS to intercept both library calls and syscalls, covering dynamic, static and semi-static binaries. By intercepting file system access directly, this approach lets cunoFS support URI-based access in additional to regular path-based access.
cunoFS also supports running as a FUSE mount, but this can affect performance, and may result in half the performance compared to running under cunoFS Direct mode, though this is still highly performant compared with alternative tools.
cunoFS FlexMount mode
There are some cases (such as snap, flatpak, and appimage applications) which cunoFS Direct mode doesn’t intercept. We are improving cunoFS Direct mode to cover these cases as well. In the meantime, cunoFS FlexMount mode combines a FUSE mount with cunoFS Direct mode, so that where possible the Direct mode is used for performance, and otherwise applications can fall back to using FUSE mode for compatibility.
POSIX metadata encoding
Another key problem cunoFS solves is how it handles encoding of POSIX metadata. Some other approaches, like s3fs, store this metadata within each object. This means that modifying metadata, or querying a directory of metadata become very expensive operations. For example, retrieving a POSIX directory listing of a thousand files would require a thousand API calls to individually check the POSIX metadata of each object. Competing approaches use a separate database server that stores the metadata elsewhere. This results in the POSIX data being split between the object store and the database, introducing their own set of problems.
With cunoFS (except in Fusion mode), the metadata is encoded directly on object storage within a special metadata folder. The cunoFS team realized that POSIX metadata within each directory tends to be highly compressible, since files and directories tended to cluster around similar names, modes, permissions and even timestamps. As experts in compression, the team managed to reduce this metadata so that it could be encoded in the filename of hidden objects. This means, for example, that a directory listing of a thousand files could retrieve the metadata (encoded in filenames) at the same time as retrieving the actual filenames in the directory.
Smarter Prefetching
As a result of running on the client node, and even intercepting the application that is being run, cunoFS has much deeper insight into application behaviour than ordinary shared file systems. This enables cunoFS to peek into an application and intelligently prefetch according to each application’s predicted usage. Object storage typically has higher latencies than ordinary file systems, thus high quality predictions can be essential to delivering high performance.
FAQ
Do you compress or deduplicate the data?
We do NOT compress or deduplicate data – this is actually an explicit design goal.
Our team has written compressed, encrypted and deduplicated file systems previously. It is actually technically far more challenging to map files to objects in a 1-to-1 fashion that is both POSIX compatible and directly accessible on the S3 interface (versus having a separate database that assembles chunks together into files).
Talking with multiple organizations it became clear that scrambling data (which is needed for compression/dedupe) or requiring an S3-to-S3 gateway to translate between scrambled and unscrambled formats was unacceptable for them. Indeed many organizations we talked to had already tried such solutions in the past and reported unacceptably low performance and scalability. Our focus was on making POSIX on object work at high performance. Furthermore, the bulk of customer data footprint in these organizations tends to already be compressed, and thus hard to dedupe – for example image, video or omics datasets.
Is cuno a special shell you’ve written?
No, the cuno command merely enables cunoFS Direct mode to intercept the user’s preferred shell, whether that is bash, zsh, csh, or something else. Tab completion and other actions are due to the support within the existing shell, rather than because of cuno doing something. Running commands like ls actually launches the unmodified ls binary installed on the system.
Does cunoFS work with software I’ve written in C/C++, Java, Python, Go, Rust, etc?
Yes, cunoFS is designed to work with any software, including software that you’ve written yourself. Note that some applications may parse URIs and treat them separately. In those cases we recommend you use path-style access. Alternatively add the application to the uricompat option in cunoFS Direct mode to intercept command line URI arguments.
Do you support Windows and Mac?
We are working on native Windows and Mac clients. In the meantime we support Windows via WSL2 and Mac via Docker. Please see the user guide for instructions on how to install cunoFS on Windows and Mac.
Does cunoFS work inside Docker, Kubernetes and Singularity containers?
Yes, cunoFS can be used with containers in multiple ways:
- (i) by mounting on the host and bind-mounting into the container,
- (ii) by injecting the cuno library into an unmodified container (we provide a seamless way to do this),
- (iii) or by installing cuno inside the container.
For instructions specific to Docker and Singularity please see the user guide. Our CSI driver for Kubernetes is now available on request. Note that cunoFS does not require any special privileges to run inside a container.
Do you support multi-node POSIX consistency and locking semantics?
cunoFS Fusion (requires a Pro or Enterprise license) and cunoFS Enterprise Edition support multi-node POSIX consistency and locking semantics.